Googleを始めとした検索エンジンなどのクローラーをコントロールするためのファイル「robots.txt」の書き方や注意点などを解説します。
robots.txtとは?
robots.txt(ロボットドットテキスト/ロボッツテキスト)とは、Googleなどが情報を収集する為に使うロボット(プログラム)の制御(アクセス許可/不許可)を行うためのファイルです。
主な役割は以下の2点です。
- 指定したファイルやフォルダ(ディレクトリ)へのクローラーのアクセスを禁止する。
アクセス禁止のフォルダ内の特定のファイルだけアクセスを許可することもできる。 - sitemap.xmlのURLを指定する。
Googleに対してはサーチコンソールから指定しておけば問題はない。
Googleなどのクローラーはrobots.txtの内容を読み取り、検索結果に表示されてはいけないページをクロールの対象から除外するなど、Webサイト側で指定した動き方をします。
誤って「すべてのページをクロールしない」設定にしてしまうと、新しいページもインデックスされない、更新した内容もGoogle検索に反映されないといった事になる可能性もありますので注意が必要です。
また、特にクロールしてほしくないファイルなどがない場合には作らなくても大丈夫です。
robots.txtとセキュリティの問題
robots.txtはクロールするURLをコントロールするものですが絶対ではありません。中にはrobots.txtを無視するような「お行儀の悪い」クローラーがあるかもしれません。
また、robots.txtに「クロール禁止」と指定したとしても、他のWebサイトからリンクがあればGoogleはURLを認識できます。
さらにGoogleがこのURLはインデックスした方が良いと判断すればインデックスされることもあります。
さらに、robots.txtはルートディレクトリにあり名前も決まっていますから、誰でも簡単に閲覧することができ、「どんなフォルダがあってアクセスを制限しているのか」などが見えてしまいます。
そのため、一般公開ができないページはパスワード認証でロックをかけるといった、ユーザーのアクセス制限をきちんと行うことは必須です。
robots.txtの書き方
robots.txtは以下の命令と対象となるファイルやフォルダのURLをセットで記述します。
| 命令 | 必須かどうか | 解説 |
|---|---|---|
| User-agent | 必須 | 対象となるクローラーを指定します。 |
| Disallow | なくても問題なし | クロールを拒否するファイルやフォルダを指定します。 |
| Allow | なくても問題なし | クロールを許可するファイルやフォルダを指定します。書かれていなければクロールします。Disallowで指定したフォルダ内でもAllowで指定したファイルやフォルダはクロールします。 |
| Sitemap | なくても問題なし | sitemap.xmlのURLを指定します。複数のURLがある場合には複数指定することもできます。 |
| Noindex | サポート外 | 2019年9月以降、完全に無効になります。noindexタグを利用しましょう。 |
| Nofollow | サポート外 | サポートされていないので機能しないと考えられます。 |
| Crawl-delay | サポート外 | クロールのアクセス頻度を調整する命令ですがGoogleはサポートしていません。 |
【User-agent】ユーザーエージェントの指定
ユーザーエージェントとは、アクセスしたプログラムを指定する名前です。
ユーザーエージェントを指定することで以下の命令の対象となるクローラーを指定します。
通常は、アクセスするすべてのユーザーエージェントを対象にしますので、*(アスタリスク)を設定します。
- User-agent: *
- すべてのクローラーを対象にする
- User-agent: Googlebot
- Googlebot(Googleのクローラー)だけを対象にする
コントロールしたいクローラーのユーザーエージェントが分からないときは、Robots Database で確認してみてください。
すべてのクローラーを網羅しているわけではありませんが、主要なクローラーのユーザーエージェントはこのサイトで分かるはずです。
クロールを許可する/許可しないフォルダの指定
ユーザーエージェントで指定したクローラーにアクセスを許可するフォルダ、許可しないフォルダを、以下の書式で指定します。
クローラーのアクセスを許可しないフォルダやファイルを指定します。
- Disallow: /
- サイトのすべてのフォルダ・ページへのアクセスを許可しない
- Disallow: /fruits/
- ドメイントップに存在するfruitsフォルダへのアクセスを許可しない
クローラーのアクセスを拒否しているフォルダ内で、アクセスを許可するファイル(URL)がある場合に設定します。何も指定がなければクローラーへのアクセスを許可している意味になりますので、アクセスを許可するフォルダをAllowで指定する必要はありません。
- Disallow: /fruits/
Allow: /fruits/apple.html - fruitsフォルダ内のapple.htmlへのアクセスだけを許可する
パターンマッチングを使う
パターンマッチングとは、パターンに合ったものだけを指定する方法です。パターンマッチングを使えば、あるフォルダ内のgif画像だけを指定するといった事が、たったの1行で指定できます。
*(アスタリスク)は「1文字以上の文字」を意味します。特定の文字で始まるといった場合などに使います。
- Disallow: /fruits/a*
- fruitsフォルダ内のaから始まるURLすべてを指定してクロールを拒否
$(ドルマーク)は末尾の文字をマッチングします。
- Disallow: /fruits/*.gif$
- fruitsフォルダ内の.gifで終わるURLすべてを指定してクロールを拒否
Googleはページで使用しているJavaScriptやCSS、画像ファイルも一緒にクロールしてページの内容を評価していますので、JavaScriptが格納されているフォルダや、CSSをrobots.txtでブロックしないようにしましょう。
ページで使用するリソースファイルがrobots.txtでブロックされていないかどうかはURL検査ツールのライブテスト(公開されたURLのテスト)機能を使えば確認できます。
詳しくはURL検査ツールの使い方で解説していますので、あわせてお読みください。
また、Googlebotは大文字と小文字を区別します。
「aaa.html」と「AAA.html」、「bbb.jpg」と「bbb.JPG」は別のURLとして処理されますので注意しましょう。
サイトマップの場所を指定する
robots.txtでは、sitemap.xmlの場所を指定する事もでき、クローラーにそのURLを伝える役目を持っています。
sitemap.xmlファイルのURLを指定します。複数のsitemap.xmlファイルに分割している場合など、複数のURLを記述しても問題はありません。
また、サイトマップインデックスファイルの場合は、そのURLのみを指定すれば大丈夫です。
- Sitemap:http://hogehoge.com/sitemap.xml
- サイトマップとしてhttp://hogehoge.com/sitemap.xmlを指定
- Sitemap:http://hogehoge.com/sitemap-1.xml
Sitemap:http://hogehoge.com/sitemap-2.xml - 2つのsitemap.xmlに分割している場合
robots.txtの記述ミスを確認する方法
サーチコンソールのrobots.txtテスターを使って、robots.txtの記述ミスだけでなく実際のGooglebotの動きを事前にシミュレートすることができます。
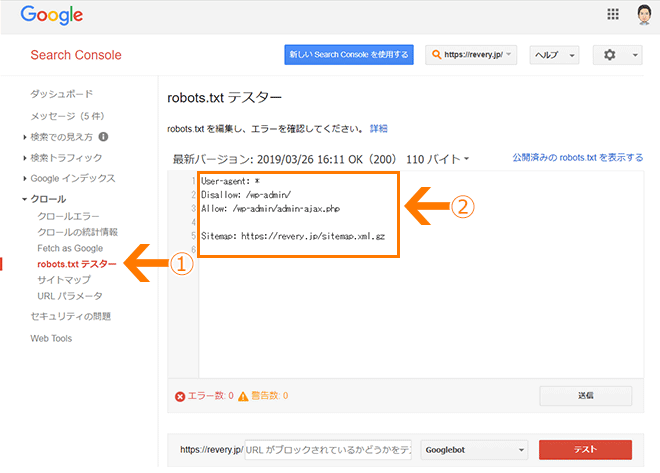
①「クロール」の「robots.txtテスター」をクリック
②robots.txtのエディタ画面。すでにrobots.txtが公開されている場合はその内容を表示。
画面の下に「エラー数」と「警告数」が表示され、問題がある場合はすぐに分かります。
まだrobots.txtを公開していない場合は、テスター画面のエディタにrobots.txtの命令を記述すると、すぐにスペルミスなどのエラーチェックができます。
Googlebotの動作確認をする方法
robots.txtのエディタ画面で編集した内容で実際にGooglebotがコントロールできるかどうか検証する機能があります。
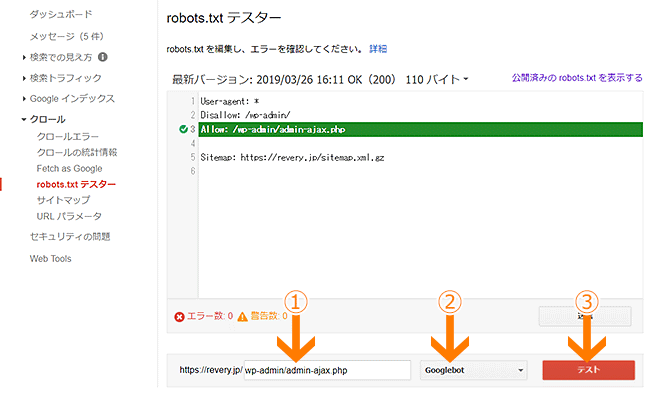
①Googlebotの動きを検証するURLを入力
②検証するGooglebotの種類(PCならGooglebot、スマホならGooglebot-Mobileなど)を選択
③「テスト」をクリック
検証したURLのアクセスが拒否される設定になっていれば「ブロック済み」と表示されます。
robots.txtがGooglebotに対して正しい設定になっているか確認してから公開しましょう。
Googleにrobots.txtの更新を伝える方法
エディタに入力した内容をダウンロードし公開したあと、「送信」ボタンをクリックしてrobots.txtの更新をGoogleに伝える(リクエストする)ことができます。
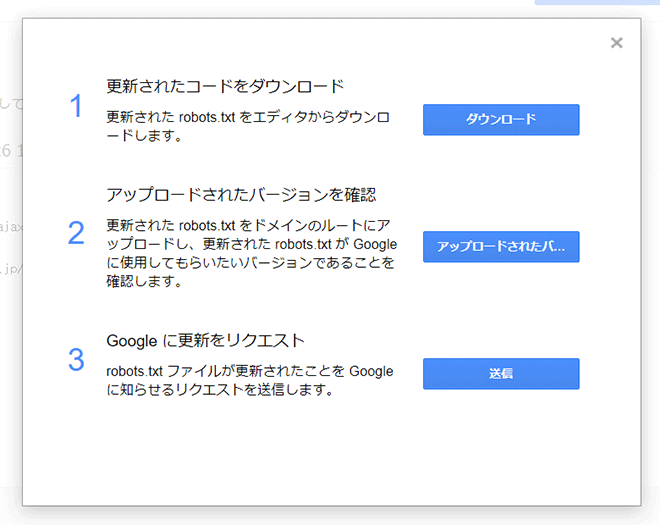
①「ダウンロード」をクリックしてエディタに書かれた内容をファイルとしてダウンロード
②ダウンロードしたrobotx.txtをFTPで公開したら「アップロードされたバ…」をクリックして公開バージョンのrobotx.txtの内容を確認
③問題なければ「送信」をクリックしてGoogleにrobots.txtの更新を知らせる
よくある質問
robots.txtに関してよく質問されることとその回答を集めました。
| Q | すでにインデックスされているページを検索結果に表示させないようにしたいのですが、そのページにnoindexタグを設置してrobots.txtでクローラーをブロックすれば大丈夫でしょうか? |
|---|---|
| A |
インデックスされているページを検索結果から消したいときに、noindexタグとrobots.txtでのクローラーブロックを併用してはいけません。
robots.txtでのクローラーのアクセスを拒否してしまうと、設置したnoindexタグの存在をGooglebotが認識できないからです。 検索結果に表示させたくないページにnoindexタグを設置しておくだけで大丈夫です。 |
まとめ
robots.txtはGooglebotをコントロールするための有効な手段ですが「絶対」ではありません。
インデックスしてほしくないコンテンツはrobotx.txtでブロックするのではなく、noindexタグを使用したりパスワードによる認証をかけるなど別の方法を使用しましょう。



井上 憲作
1975年生まれ。PCパーツの通販サイト管理者から、大手インターネット広告代理店にて、100社以上のコンサルティングやSEO施策に従事したのち、2018年に独立。趣味はスキューバダイビング。









